
「HTMLを解析する」Beautiful Soupを使って。
インターネット上の情報をスクレイピングして情報を書き出したはいいけれど、自分の目当ての情報だけを集めたい。 そんなときに便利なのが「Beautiful Soup」というライブラリ。外部ライブラリなのでまずはインストールしましょう。
Windowsならば、コマンドプロンプトを使って、「pip install beautifulsoup4」とします。
macOSならばターミナルを使い、「pip3 install beautifulsoup4」とします。
Beautiful Soupを使ってHTMLを解析してみよう
解説
| import requests | 事前にコマンドプロンプトでインストールしたインターネットにアクセス命令する外部ライブラリ「requests」、これをimportします。 |
| from bs4 import BeautifulSoup | 事前にコマンドプロンプトでインストールしたHTMLを解析する外部ライブラリ「BeautifulSoup」、これが入っているbs4というパッケージからBeautifulSoupをimport |
| load_url = “https://www.ymori.com/books/python2nen/test1.html” | 変数load_urlに解析するWEBページアドレスを代入 |
| html = requests.get(load_url) | 変数htmlにネット上のHTMLファイルを読み込む命令のrequests.get(load_url)を代入します。 |
| soup = BeautifulSoup(html.content, “html.parser”) | 変数soupにBeautifulSoupを使ったHTML解析の命令を代入します。 |
| print(soup) | データを表示します。 |
実行結果
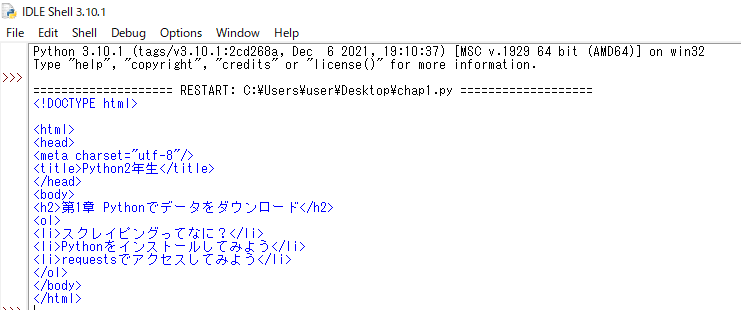
そのまま表示はされていますが、これが解析したあとの状態になります。
ここから、自分の目的にあった「要素」を取り出していきます。
取り出し方は「.find(“タグ名)”」するだけです。
では、早速やってみましょう。
titleタグ、h2タグ、liタグを検索して、取り出し表示してみましょう。
実行結果
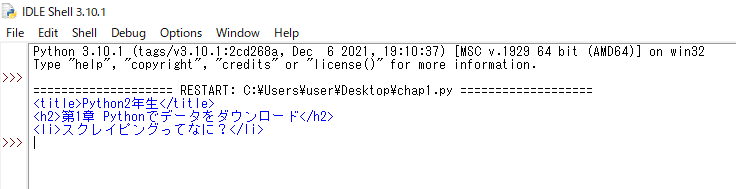
指定した要素の3つが表示されました。
タグがついたままなので、文字だけを取り出すには最後に「.text」をつけます。
実行結果
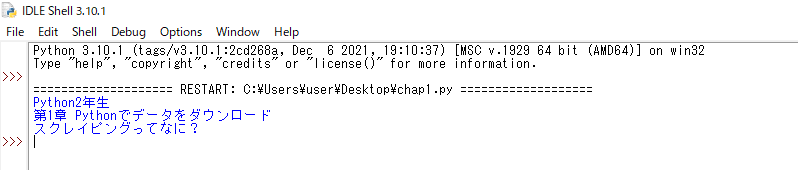
*尚、ここではバージョン「Python 3.10.1」を使用しています。

この本から引用、参考に学び、完成させることができました。しかし、ここではプログラミング初心者の私が詳しく解説することは、おこがましく、難しく出来ません(ToT)
その点、この本では丁寧な解説が載っていますので、解説とともにコードを書き、完成させればより深く学ぶことができます(^.^)、実際、初心者の私でもわかりやすかったです。身に付け消えないスキルが2,000円程ならコスパよく、買っておいてよかったと満足してます。
わからないことはプロフェッショナルから学ぶのが一番
キャリアアップに必要なスキルを取得しよう。
オンラインで受講ができるスクールですので、全国どこからでも。