
クローリング
ネット上には公開されているいろいろな情報があり、私たちはそれを集めることができます。 プログラミングではそれらを自動で集めることもできます。 このネット上に公開されているデータを集めることを「クローリング」といいます。
スクレイピング
集めたデータを解析して、必要なデータを取り出すこと。
Pythonはネットへアクセスするライブラリが豊富でクローリングやスクレイピングがしやすいプログラミング言語となります。
ただし、気をつけないといけないこと
手作業でデータを収集するよりも、簡単に大量のデータを収集できるの便利ですが、気をつけるべきことがあります。 相手の作ったサイトに迷惑をかけないことです。 主に下記の3つのことを厳守しましょう。
著作権を守ること
著作権についての注意をよく確認し、無断で複製したり二次利用しないこと。 比較的、安心して利用できるのは、利用されることを前提に作成された公的機関や企業などが公開している情報です。しかし、そこでもよく著作権について確認してから収集しましょう。
アクセスをしすぎて業務妨害をしないこと
サーバーに大量にアクセスすると相手のサーバーに負担をかけることになり、結果的に業務を妨害することになりかねません。 そこでプログラム側でアクセス頻度のしくみをつくり(1回アクセスしたら3秒待つなど)業務妨害にならないように工夫しましょう。
クローリング禁止のところにはクローリングしないこと
相手サイト側でクローリングしないでほしいとすることが明示されていたら止めましょう。 「robots.txt」というファイルや、HTML内の「robots metaタグ」に書いてあります。
「robots.txt」
「robots.txt」はサイトのルートディレクトリに書いてあり、このファイルの有無を確認し、また下記のようにかいてあったらクローリングしないでほしいということなので止めましょう。
User-agent:*
Disallow:/
「robots metaタグ」
<meta name=”robots” content=”nofollow”>
このように書いてあった場合は、「このページ内のリンクをたどらないでもらいたい」ということなのでクローリングは止めましょう。
requestsでアクセスをする
requestsは外部ライブラリであり、インターネットに簡単にアクセスできます。
通常の情報収集
調べたいキーワードで検索したりURLを入力しリクエストを送る → 「表示するのに必要なデータを取得」 → WEBブラウザで表示
Pythonにて情報収集
requestsライブラリで書かれたPythonのプログラムでリクエストする → 「表示するのに必要なデータを取得」 → 解析、データ取り出し
外部ライブラリをインストールする
Windowsではコマンドプロンプトを起動。
Windowsシステムツール → コマンドプロンプト → pipコマンドでインストール (例えばrequestsであれば、、、「pip install requests」)
macOSではターミナルを起動
「アプリケーション」フォルダ内の「ユーティリティ」フォルダにあるターミナル.appをクリック。pip3コマンドでインストール。
HTMLファイルを読み込む
IDLEを起動してプログラムを書いてみましょう。
Windowsではスタートメニューから。macOSでは「アプリケーション」フォルダから。
解説
| import requests | 事前にコマンドプロンプトでインストールしたインターネットにアクセス命令する外部ライブラリ「requests」、これをimportします。 |
| url = “https://www.ymori.com/books/python2nen/test1.html” | 変数urlに解析するWEBページアドレスを代入 |
| response = requests.get(url) | 変数responseにネット上のHTMLファイルを読み込む命令のrequests.get(url)を代入します。 |
| response.encoding = response.apparent_encoding | .apparent_encodingで文字化けしないように正しく表示できる文字コードを自動選択する。 |
| print(response.text) | 文字列だけを取り出す.textをつけてデータを表示します。 |
出力結果
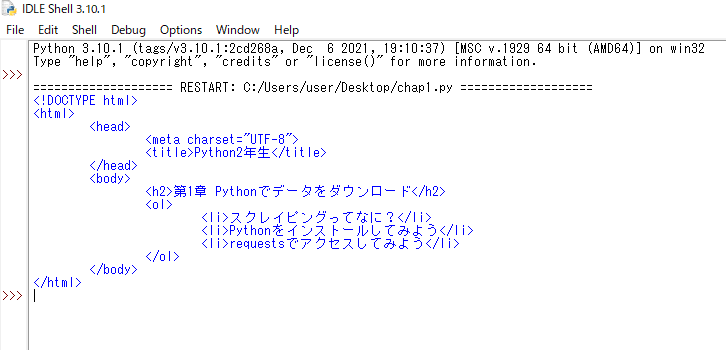
解説
requests.getで取得できるいろいろな情報
| .text | 文字列データ |
| .content | バイナリーデータ(コンピュータが理解しやすいデータ (2進数で表現されたデータ)画像や音声や動画 |
| .url | アクセスしたurl |
| .apparent_encoding | 推測させるコーディング方式 |
| .status_code | HTTPステータスコード(200はOK、404はみつからなかったなど) |
| .headers | レスポンスヘッダー(HTTPレスポンスを構成する3つの部品のひとつであり、「HTTPステータスラインに書ききれないレスポンスの情報」が書かれている場所) |
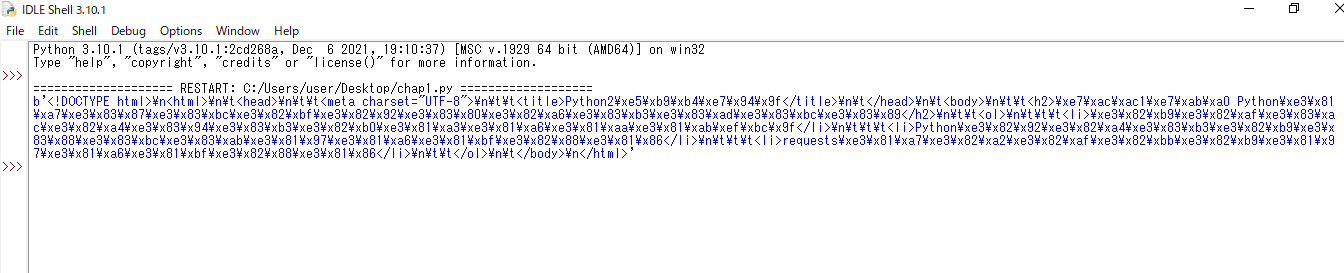
「.content」で取得した場合
「.url」で取得した場合

「.apparent_encoding」で取得した場合

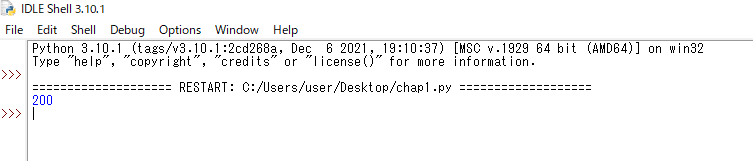
「.status_code」で取得した場合
「.headers」で取得した場合

*尚、ここではバージョン「Python 3.10.1」を使用しています。

この本から引用、参考に学び、完成させることができました。しかし、ここではプログラミング初心者の私が詳しく解説することは、おこがましく、難しく出来ません(ToT)
その点、この本では丁寧な解説が載っていますので、解説とともにコードを書き、完成させればより深く学ぶことができます(^.^)、実際、初心者の私でもわかりやすかったです。身に付け消えないスキルが2,000円程ならコスパよく、買っておいてよかったと満足してます。
わからないことはプロフェッショナルから学ぶのが一番
キャリアアップに必要なスキルを取得しよう。
オンラインで受講ができるスクールですので、全国どこからでも。