
前回はすべてのリンクタグのhref属性を取り出す方法を学びました。
そこでは下記のように、2つあったリンクタグの内、一つはそのままアクセスできるURLとしての「絶対URL」、もう一つは「このページから見てどこにあるか」という「相対URL」でした。
「絶対URL」はそのままURLとして使えますが、「相対URL」はそのままでは使えません。
そこで今回は「相対URL」を「絶対URL」に変換する方法を学びましょう。
完成はこんな感じです。

すべてのリンクタグのhref属性を絶対URLに変換して表示させてみましょう。
変換するには「urllibライブラリ」の「parse.urljoin(ベースURL, 調べるURL)」を使います。
ベースURLとは、どのページから見たURLなのかを意味します。
調べるURLが絶対URLなら「そのままのURL」を、相対URLなら「ベースURLと連結させた絶対URL」を返します。
では、早速urllibをimportして、URLの変換処理をしてみましょう。
解説
| import requests | 事前にコマンドプロンプトでインストールしたインターネットにアクセス命令する外部ライブラリ「requests」、これをimportします。 |
| from bs4 import BeautifulSoup | 事前にコマンドプロンプトでインストールしたHTMLを解析する外部ライブラリ「BeautifulSoup」、これが入っているbs4というパッケージからBeautifulSoupをimport |
| import urllib | 相対URLを絶対URLに変換するurllibライブラリをimport |
| load_url = “https://www.roadtoupload.com/学びファイル/python2年生/Python_sample2.html” | 変数load_urlに解析するWEBページアドレスを代入 |
| html = requests.get(load_url) | 変数htmlにネット上のHTMLファイルを読み込む命令のrequests.get(load_url)を代入します。 |
| soup = BeautifulSoup(html.content, “html.parser”) | 変数soupにBeautifulSoupを使ったHTML解析の命令を代入します。 |
| for element in soup.find_all(“a”): | リストから1つずつ取り出すためfor文を使用し、すべてのaタグを探しリストで返すfind_all(”a”)とします。 |
| print(element.text) | 取得した文字列データを表示します。 |
| url = element.get(“href”) | href属性を取得し、それを変数urlとします。 |
| link_url = urllib.parse.urljoin(load_url, url) | 相対URLを絶対URLに変換する命令をします。それを変数link_urlとします。 |
| print(link_url) | 取得したデータを表示します。 |
実行結果
(../Python一年生/Python1年生_17.html)という相対リンクであったのが、絶対リンクに変換されて表示できました。
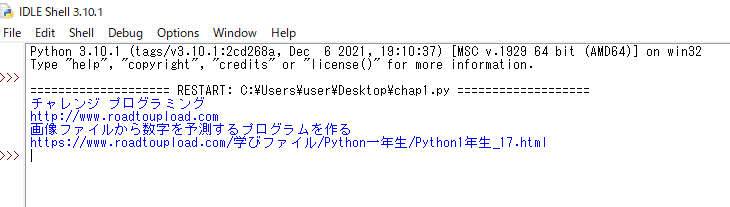
それでは、取り出したものでファイルを作成し、それに書き込むプログラムを作ってみましょう。
実行結果
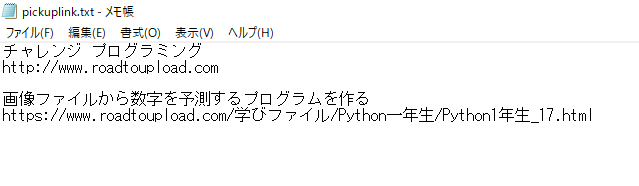
うまくファイルに書き込めました。
尚、改行コードがないと全部つながって見にくくなってしまうので、「+”\n”」を使用して改行しています。*尚、ここではバージョン「Python 3.10.1」を使用しています。

この本から引用、参考に学び、完成させることができました。しかし、ここではプログラミング初心者の私が詳しく解説することは、おこがましく、難しく出来ません(ToT)
その点、この本では丁寧な解説が載っていますので、解説とともにコードを書き、完成させればより深く学ぶことができます(^.^)、実際、初心者の私でもわかりやすかったです。身に付け消えないスキルが2,000円程ならコスパよく、買っておいてよかったと満足してます。
わからないことはプロフェッショナルから学ぶのが一番
キャリアアップに必要なスキルを取得しよう。
オンラインで受講ができるスクールですので、全国どこからでも。