
オープンデータをダウンロードして分析する。
オープンデータとはネット上で公的機関や企業などが公開している自由に使ってもいいデータのことで、基本的に著作権などのライセンス制限がない。郵便局のオープンデータを使ってみよう
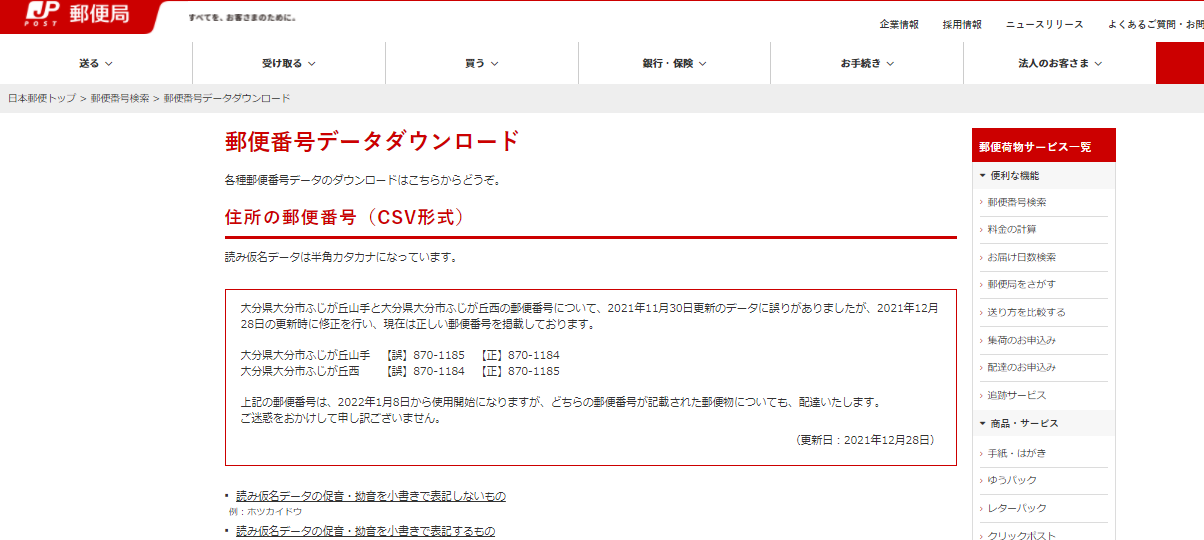 今回はこちらのページから「読み仮名データの促音・拗音を小書きで表記するもの」を活用します。
そして、東京都のデータをクリックして、ダウンロードします。
今回はこちらのページから「読み仮名データの促音・拗音を小書きで表記するもの」を活用します。
そして、東京都のデータをクリックして、ダウンロードします。

ファイルをダウンロード

ファイルの中はこんな感じです。
 それでは文字列やデータ数が含まれているのか、読み取ってみましょう。
それでは文字列やデータ数が含まれているのか、読み取ってみましょう。
解説
| import pandas as pd | 表データーを読み込むpandasライブラリをimportします。省略してpdとします。 |
| df = pd.read_csv(“13TOKYO.CSV”, header=None, encoding=”shift_jis”) | 1行目から書かれているのでヘッダーはありません。日本語はshift JISが使われています。pandasのデフォルトはUTF-8形式で読み込むようになっています。したがってencoding=”shift_jis”と指定が必要。 |
| print(len(df)) | 要素数や文字数を取得します |
| print(df.columns.values) | 実際のデータの値を取得します。 |
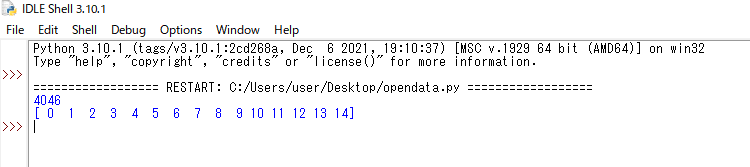
14列あり、4046のデータが含まれていることがわかりました。
データを抽出してみよう
郵便番号が「1020072」のデータを抽出して住所を表示してみましょう。
解説
| import pandas as pd | 表データーを読み込むpandasライブラリをimportします。省略してpdとします。 |
| df = pd.read_csv(“13TOKYO.CSV”, header=None, encoding=”shift_jis”) | 1行目から書かれているのでヘッダーはありません。日本語はshift JISが使われています。pandasのデフォルトはUTF-8形式で読み込むようになっています。したがってencoding=”shift_jis”と指定が必要。 |
| results = df[df[2] == 1020072] | 指定した郵便番号を抽出するには、df[df[“列”]==”文字列”]とし、変数resultsに代入します。郵便番号7桁は、ここでは0から数えて3列目にあるので2と指定してます。 |
| print(results[[2,6,7,8]]) | 0から数えて郵便番号のある2、都道府県のある6、区のある7、地名のある8を指定します。 |
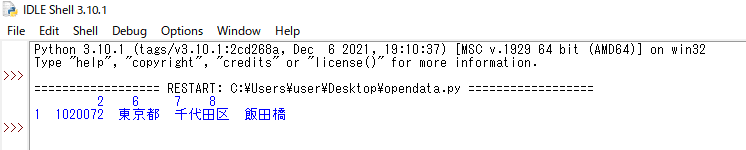
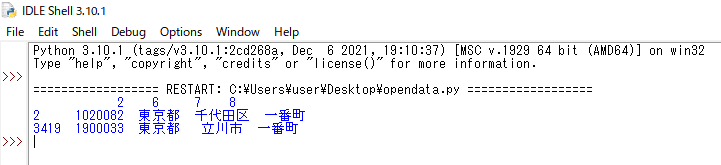
指定したデータを抽出できました。どうぞ下記の2行目のデータと照合してみてください。

部分的に一致したデータを抽出する
今回は住所が「一番町」という文字を含んだデータを調べてみます。まずは3行目にありますね。他にあるのでしょうか?調べてみましょう。
解説
| import pandas as pd | 表データーを読み込むpandasライブラリをimportします。省略してpdとします。 |
| df = pd.read_csv(“13TOKYO.CSV”, header=None, encoding=”shift_jis”) | 1行目から書かれているのでヘッダーはありません。日本語はshift JISが使われています。pandasのデフォルトはUTF-8形式で読み込むようになっています。したがってencoding=”shift_jis”と指定が必要。 |
| results = df[df[8].str.contains(“一番町”)] | 部分的に一致するものを抽出するには、df[df.str.contains(“文字列”)]と指定します。 |
| print(results[[2,6,7,8]]) | 0から数えて郵便番号のある2、都道府県のある6、区のある7、地名のある8を指定します。 |
お?3行目以外にももう一つ「一番町」というところが抽出できました。
*尚、ここではバージョン「Python 3.10.1」を使用しています。

この本から引用、参考に学び、完成させることができました。しかし、ここではプログラミング初心者の私が詳しく解説することは、おこがましく、難しく出来ません(ToT)
その点、この本では丁寧な解説が載っていますので、解説とともにコードを書き、完成させればより深く学ぶことができます(^.^)、実際、初心者の私でもわかりやすかったです。身に付け消えないスキルが2,000円程ならコスパよく、買っておいてよかったと満足してます。
わからないことはプロフェッショナルから学ぶのが一番
キャリアアップに必要なスキルを取得しよう。
オンラインで受講ができるスクールですので、全国どこからでも。